

Massive language fashions and the purposes they energy allow unprecedented alternatives for organizations to get deeper insights from their knowledge reservoirs and to construct solely new courses of purposes.
However with alternatives usually come challenges.
Each on premises and within the cloud, purposes which might be anticipated to run in actual time place important calls for on knowledge heart infrastructure to concurrently ship excessive throughput and low latency with one platform funding.
To drive steady efficiency enhancements and enhance the return on infrastructure investments, NVIDIA commonly optimizes the state-of-the-art neighborhood fashions, together with Meta’s Llama, Google’s Gemma, Microsoft’s Phi and our personal NVLM-D-72B, launched only a few weeks in the past.
Relentless Enhancements
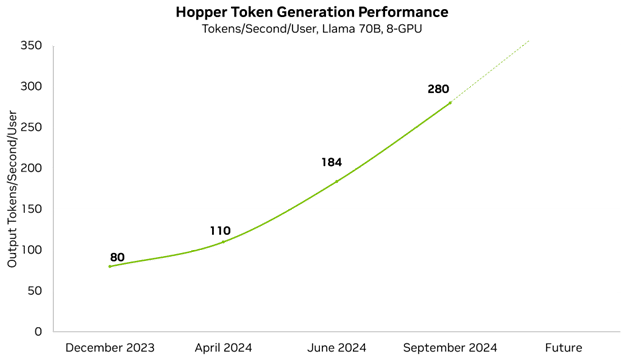
Efficiency enhancements let our clients and companions serve extra complicated fashions and cut back the wanted infrastructure to host them. NVIDIA optimizes efficiency at each layer of the expertise stack, together with TensorRT-LLM, a purpose-built library to ship state-of-the-art efficiency on the most recent LLMs. With enhancements to the open-source Llama 70B mannequin, which delivers very excessive accuracy, we’ve already improved minimal latency efficiency by 3.5x in lower than a yr.
We’re continually enhancing our platform efficiency and commonly publish efficiency updates. Every week, enhancements to NVIDIA software program libraries are revealed, permitting clients to get extra from the exact same GPUs. For instance, in only a few months’ time, we’ve improved our low-latency Llama 70B efficiency by 3.5x.
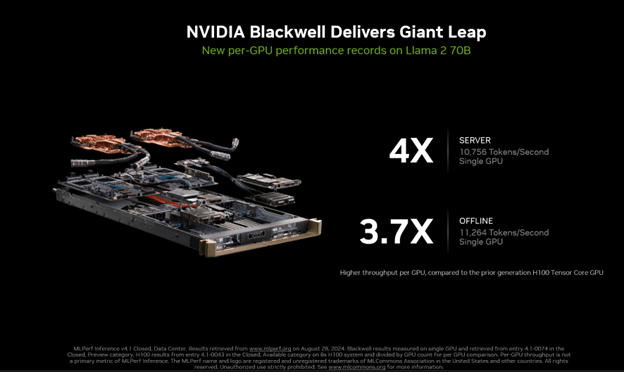
In the latest spherical of MLPerf Inference 4.1, we made our first-ever submission with the Blackwell platform. It delivered 4x extra efficiency than the earlier era.
This submission was additionally the first-ever MLPerf submission to make use of FP4 precision. Narrower precision codecs, like FP4, reduces reminiscence footprint and reminiscence visitors, and in addition increase computational throughput. The method takes benefit of Blackwell’s second-generation Transformer Engine, and with superior quantization strategies which might be a part of TensorRT Mannequin Optimizer, the Blackwell submission met the strict accuracy targets of the MLPerf benchmark.
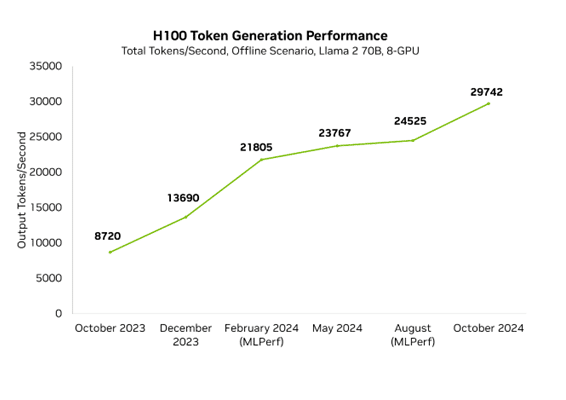
Enhancements in Blackwell haven’t stopped the continued acceleration of Hopper. Within the final yr, Hopper efficiency has elevated 3.4x in MLPerf on H100 due to common software program developments. Which means that NVIDIA’s peak efficiency right this moment, on Blackwell, is 10x quicker than it was only one yr in the past on Hopper.
Our ongoing work is integrated into TensorRT-LLM, a purpose-built library to speed up LLMs that include state-of-the-art optimizations to carry out inference effectively on NVIDIA GPUs. TensorRT-LLM is constructed on high of the TensorRT Deep Studying Inference library and leverages a lot of TensorRT’s deep studying optimizations with extra LLM-specific enhancements.
Bettering Llama in Leaps and Bounds
Extra just lately, we’ve continued optimizing variants of Meta’s Llama fashions, together with variations 3.1 and three.2 in addition to mannequin sizes 70B and the most important mannequin, 405B. These optimizations embrace customized quantization recipes, in addition to environment friendly use of parallelization strategies to extra effectively cut up the mannequin throughout a number of GPUs, leveraging NVIDIA NVLink and NVSwitch interconnect applied sciences. Chopping-edge LLMs like Llama 3.1 405B are very demanding and require the mixed efficiency of a number of state-of-the-art GPUs for quick responses.
Parallelism strategies require a {hardware} platform with a strong GPU-to-GPU interconnect cloth to get most efficiency and keep away from communication bottlenecks. Every NVIDIA H200 Tensor Core GPU options fourth-generation NVLink, which gives a whopping 900GB/s of GPU-to-GPU bandwidth. Each eight-GPU HGX H200 platform additionally ships with 4 NVLink Switches, enabling each H200 GPU to speak with every other H200 GPU at 900GB/s, concurrently.
Many LLM deployments use parallelism over selecting to maintain the workload on a single GPU, which might have compute bottlenecks. LLMs search to stability low latency and excessive throughput, with the optimum parallelization approach relying on software necessities.
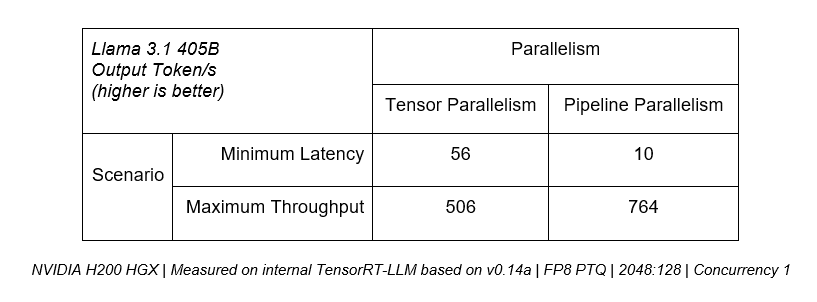
For example, if lowest latency is the precedence, tensor parallelism is vital, because the mixed compute efficiency of a number of GPUs can be utilized to serve tokens to customers extra rapidly. Nonetheless, to be used circumstances the place peak throughput throughout all customers is prioritized, pipeline parallelism can effectively increase general server throughput.
The desk beneath reveals that tensor parallelism can ship over 5x extra throughput in minimal latency eventualities, whereas pipeline parallelism brings 50% extra efficiency for optimum throughput use circumstances.
For manufacturing deployments that search to maximise throughput inside a given latency funds, a platform wants to offer the power to successfully mix each strategies like in TensorRT-LLM.
Learn the technical weblog on boosting Llama 3.1 405B throughput to be taught extra about these strategies.
The Virtuous Cycle
Over the lifecycle of our architectures, we ship important efficiency positive aspects from ongoing software program tuning and optimization. These enhancements translate into extra worth for purchasers who prepare and deploy on our platforms. They’re in a position to create extra succesful fashions and purposes and deploy their present fashions utilizing much less infrastructure, enhancing their ROI.
As new LLMs and different generative AI fashions proceed to return to market, NVIDIA will proceed to run them optimally on its platforms and make them simpler to deploy with applied sciences like NIM microservices and NIM Agent Blueprints.
Be taught extra with these sources:

{kind=link}