

Editor’s word: This submit is a part of the AI Decoded collection, which demystifies AI by making the know-how extra accessible, and showcases new {hardware}, software program, instruments and accelerations for GeForce RTX PC and NVIDIA RTX workstation customers.
Massive language fashions (LLMs) are reshaping productiveness. They’re able to drafting paperwork, summarizing internet pages and, having been skilled on huge portions of information, precisely answering questions on almost any matter.
LLMs are on the core of many rising use circumstances in generative AI, together with digital assistants, conversational avatars and customer support brokers.
Most of the newest LLMs can run domestically on PCs or workstations. That is helpful for a wide range of causes: customers can hold conversations and content material non-public on-device, use AI with out the web, or just reap the benefits of the highly effective NVIDIA GeForce RTX GPUs of their system. Different fashions, due to their dimension and complexity, do no’t match into the native GPU’s video reminiscence (VRAM) and require {hardware} in massive knowledge facilities.
Nonetheless, Iit i’s attainable to speed up a part of a immediate on a data-center-class mannequin domestically on RTX-powered PCs utilizing a method referred to as GPU offloading. This permits customers to learn from GPU acceleration with out being as restricted by GPU reminiscence constraints.
Dimension and High quality vs. Efficiency
There’s a tradeoff between the mannequin dimension and the standard of responses and the efficiency. Normally, bigger fashions ship higher-quality responses, however run extra slowly. With smaller fashions, efficiency goes up whereas high quality goes down.
This tradeoff isn’t all the time easy. There are circumstances the place efficiency could be extra essential than high quality. Some customers could prioritize accuracy to be used circumstances like content material era, since it might run within the background. A conversational assistant, in the meantime, must be quick whereas additionally offering correct responses.
Essentially the most correct LLMs, designed to run within the knowledge middle, are tens of gigabytes in dimension, and should not slot in a GPU’s reminiscence. This may historically stop the appliance from benefiting from GPU acceleration.
Nonetheless, GPU offloading makes use of a part of the LLM on the GPU and half on the CPU. This permits customers to take most benefit of GPU acceleration no matter mannequin dimension.
Optimize AI Acceleration With GPU Offloading and LM Studio
LM Studio is an software that lets customers obtain and host LLMs on their desktop or laptop computer pc, with an easy-to-use interface that permits for in depth customization in how these fashions function. LM Studio is constructed on high of llama.cpp, so it’s totally optimized to be used with GeForce RTX and NVIDIA RTX GPUs.
LM Studio and GPU offloading takes benefit of GPU acceleration to spice up the efficiency of a domestically hosted LLM, even when the mannequin can’t be totally loaded into VRAM.
With GPU offloading, LM Studio divides the mannequin into smaller chunks, or “subgraphs,” which signify layers of the mannequin structure. Subgraphs aren’t completely fastened on the GPU, however loaded and unloaded as wanted. With LM Studio’s GPU offloading slider, customers can determine what number of of those layers are processed by the GPU.
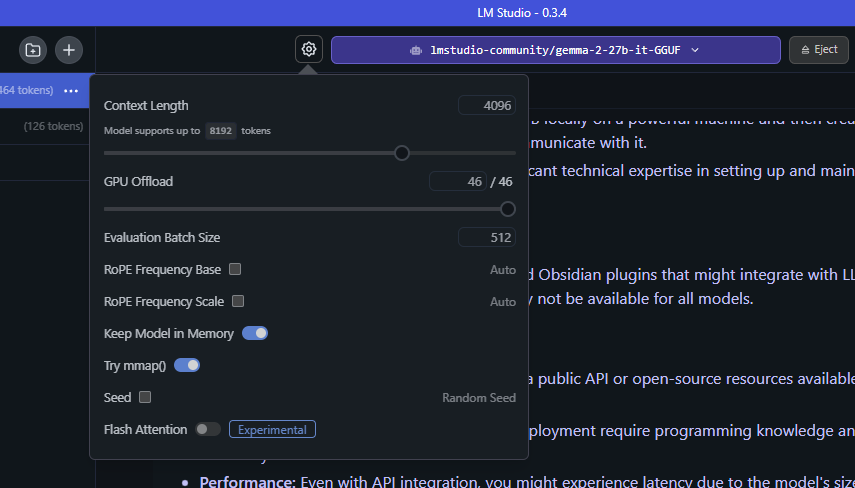
For instance, think about utilizing this GPU offloading approach with a big mannequin like Gemma-2-27B. “27B” refers back to the variety of parameters within the mannequin, informing an estimate as to how a lot reminiscence is required to run the mannequin.
In accordance with 4-bit quantization, a method for decreasing the scale of an LLM with out considerably decreasing accuracy, every parameter takes up a half byte of reminiscence. Which means that the mannequin ought to require about 13.5 billion bytes, or 13.5GB — plus some overhead, which typically ranges from 1-5GB.
Accelerating this mannequin completely on the GPU requires 19GB of VRAM, out there on the GeForce RTX 4090 desktop GPU. With GPU offloading, the mannequin can run on a system with a lower-end GPU and nonetheless profit from acceleration.
In LM Studio, it’s attainable to evaluate the efficiency influence of various ranges of GPU offloading, in contrast with CPU solely. The under desk reveals the outcomes of working the identical question throughout totally different offloading ranges on a GeForce RTX 4090 desktop GPU.

On this explicit mannequin, even customers with an 8GB GPU can take pleasure in a significant speedup versus working solely on CPUs. In fact, an 8GB GPU can all the time run a smaller mannequin that matches completely in GPU reminiscence and get full GPU acceleration.
Reaching Optimum Steadiness
LM Studio’s GPU offloading function is a robust instrument for unlocking the complete potential of LLMs designed for the information middle, like Gemma-2-27B, domestically on RTX AI PCs. It makes bigger, extra advanced fashions accessible throughout the complete lineup of PCs powered by GeForce RTX and NVIDIA RTX GPUs.
Obtain LM Studio to attempt GPU offloading on bigger fashions, or experiment with a wide range of RTX-accelerated LLMs working domestically on RTX AI PCs and workstations.
Generative AI is remodeling gaming, videoconferencing and interactive experiences of every kind. Make sense of what’s new and what’s subsequent by subscribing to the AI Decoded e-newsletter.

{kind=link}